
九、Stable Diffusion – ControlNet 控制模型安装与使用
基于扩散模型的AI绘画非常难以控制,出图充满了随机性,缺乏稳定输出能力。
ControlNet是对大扩散模型做微调的额外网络,使用一些额外输入的信息给扩散模型生成提供明确的指引。
一、ControlNet 插件下载安装
ControlNet 插件地址
GitHub – Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
在 Stable Diffusion WebUI 的 Extensions 选项卡中,输入插件地址,点击 Install
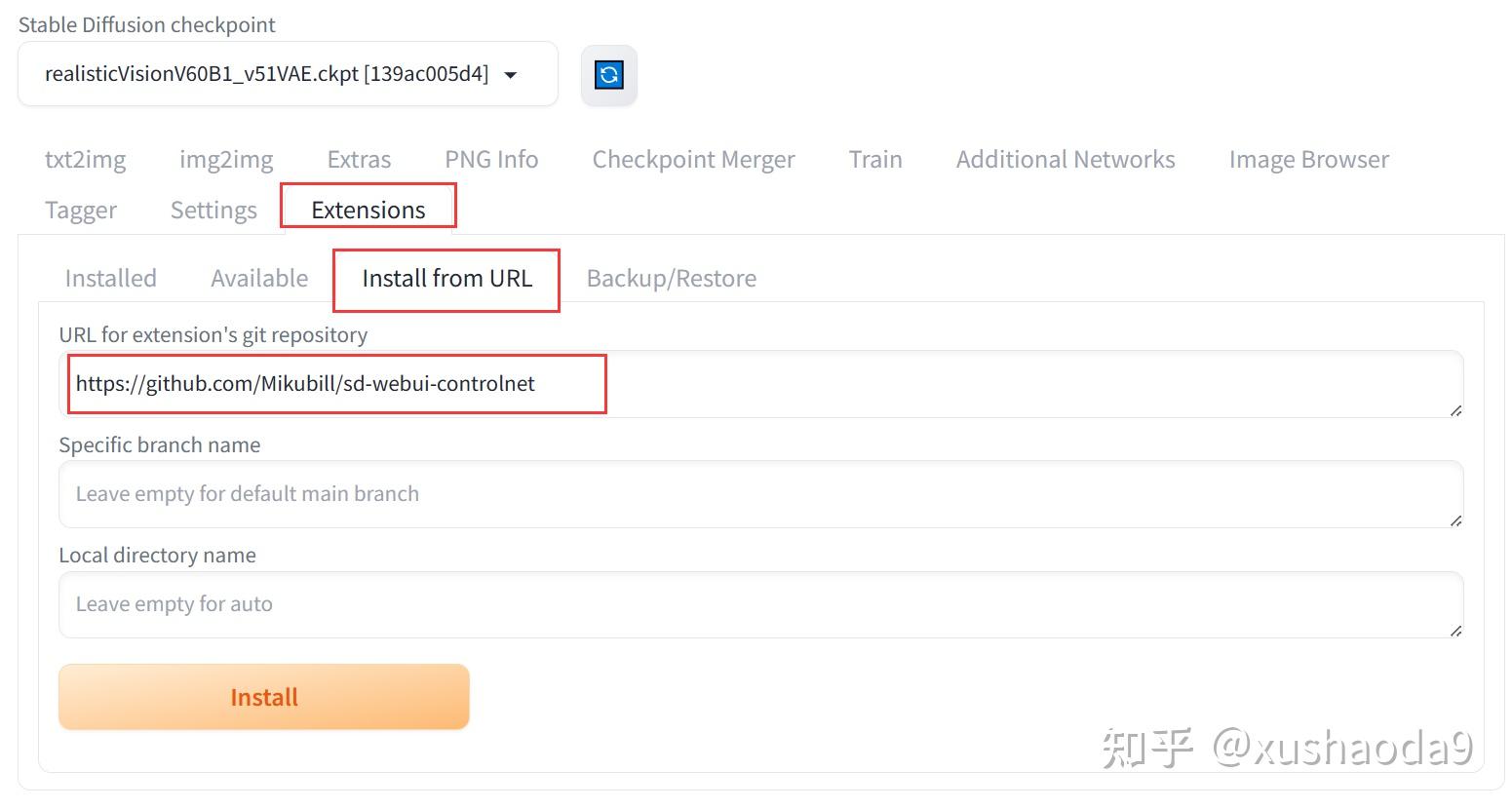
安装完成后,在 文生图、图生图选项卡下方的属性设置栏目,会出现 ControlNet 的设置选项
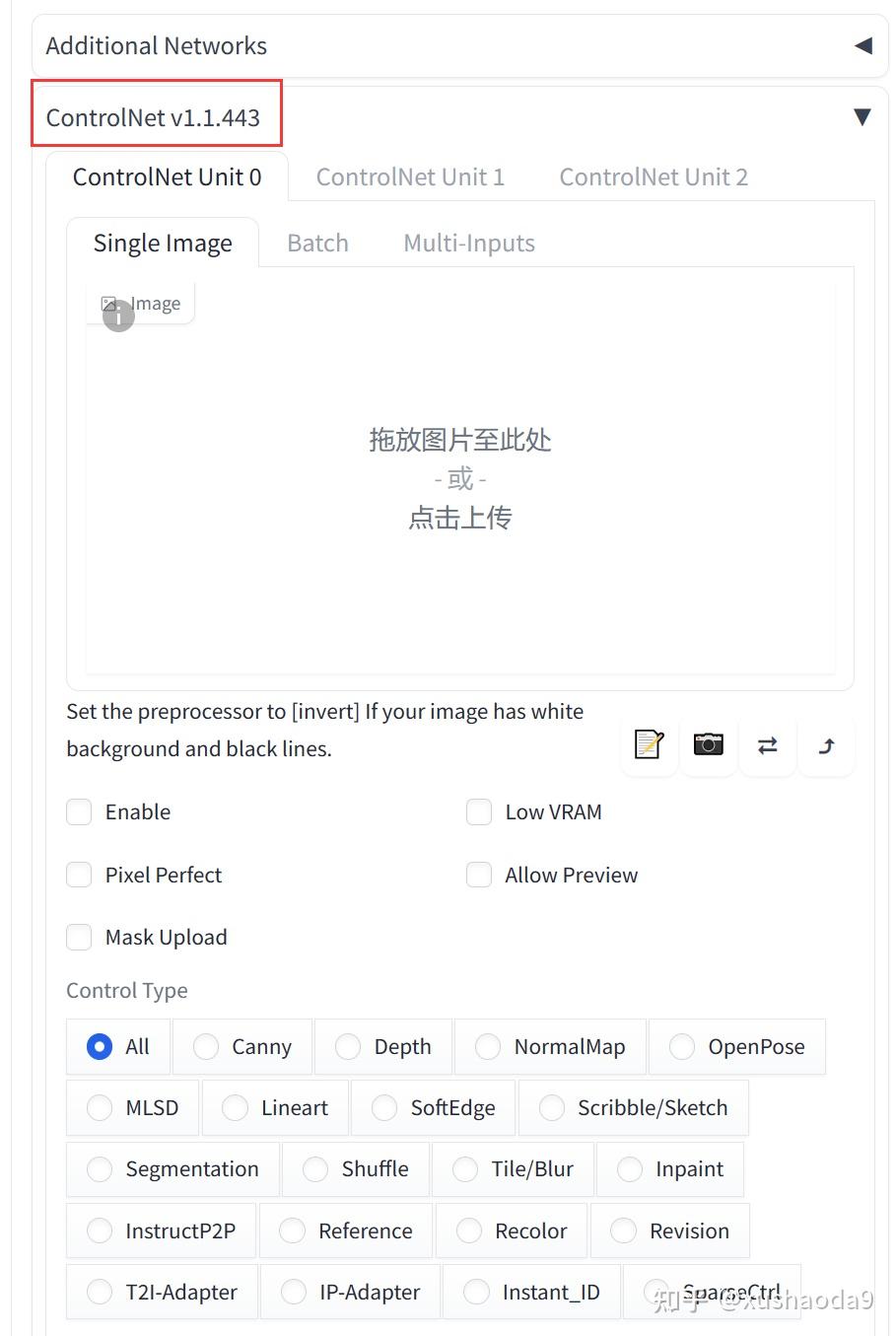
二、ControlNet 控制模型下载安装与绘图
ControlNet 需要下载控制模型才能正常工作,下面以 Openpose(动作姿势) 为例,演示控制模型下载安装及使用方法
1、下载控制模型 Openpose
Huggingface 下载地址:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
一个控制模型大约 1.4GB,需要哪个下载哪个
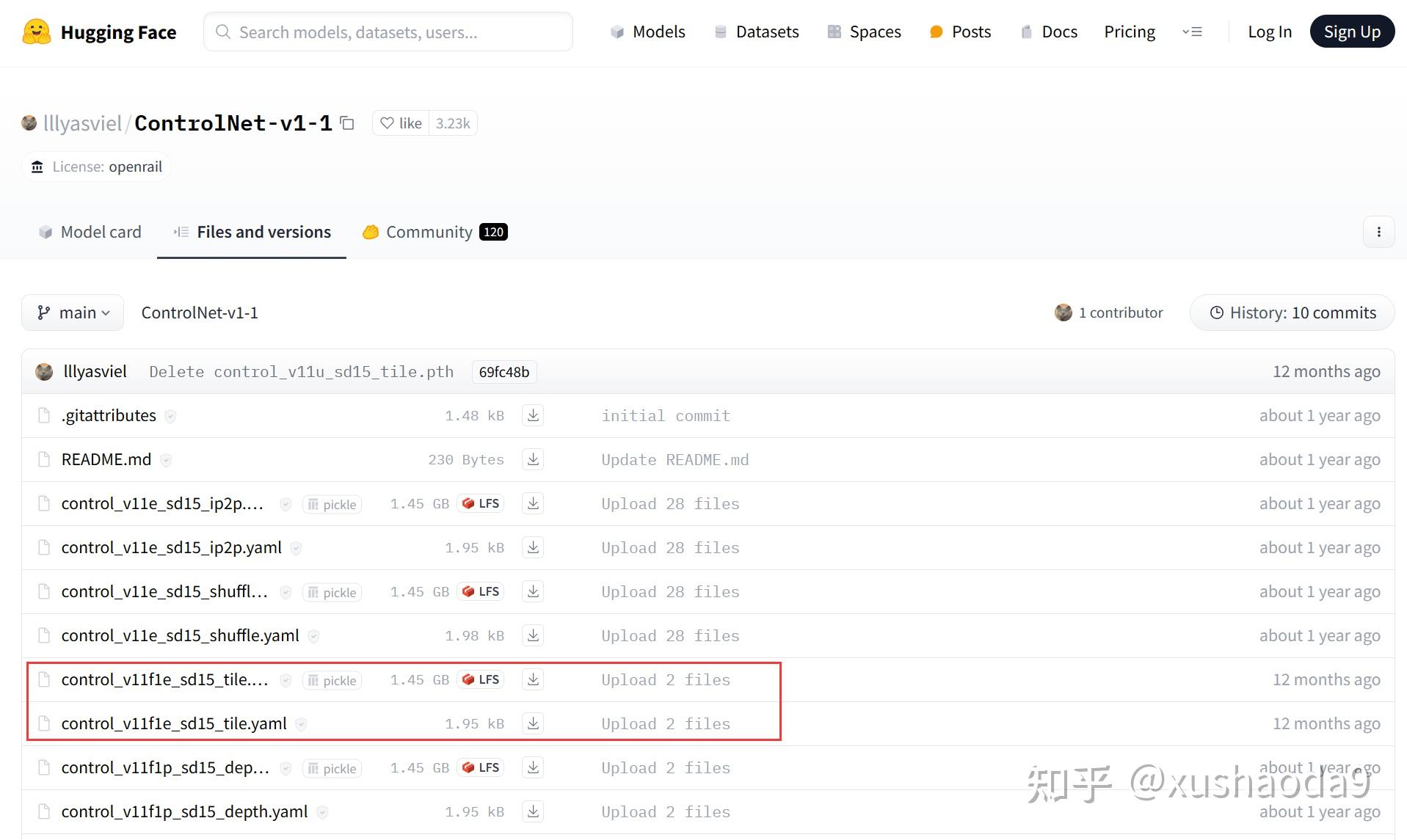
需要将模型及其对应的 yaml 配置文件均下载下来,放到 stable-diffusion-webuimodelsControlNet 文件夹内
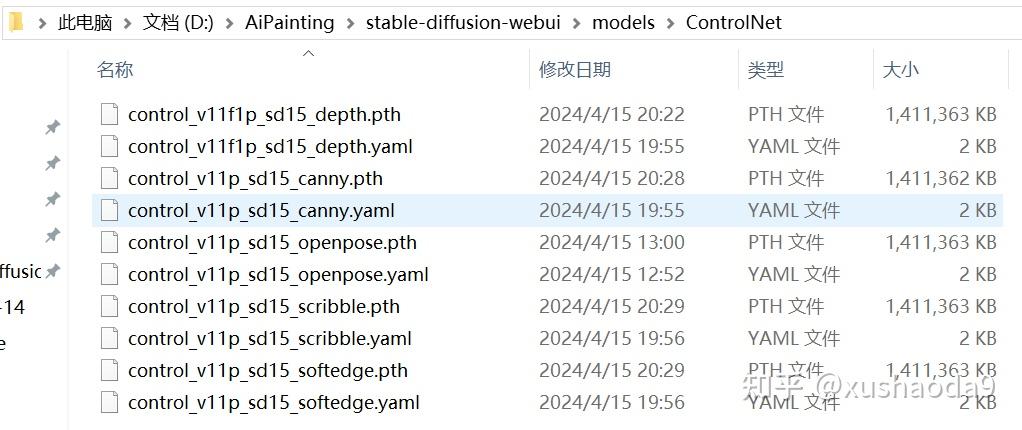
在 Stable Diffusion WebUI 的 ControlNet 参数设置选项卡,点击刷新,即可看到已完成安装的控制模型
2、下载预处理器 Annotator
只下载控制模型还不行,当画图的时候会自动下载预处理器,从图片中提取对 ControlNet 有用的信息。但是一般情况下网络都会报错,在终端会提示文件下载失败的报错信息。
以使用 Openpose 为例,终端提示错误信息为:

这时候,按照错误提示,将对应文件下载下来放到指定路径即可,下载地址及使用 Openpose 需要下载的文件如下:
https://huggingface.co/lllyasviel/Annotators/tree/main
- body_pose_model.pth
- facenet.pth
- hand_pose_model.pth
下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsopenpose

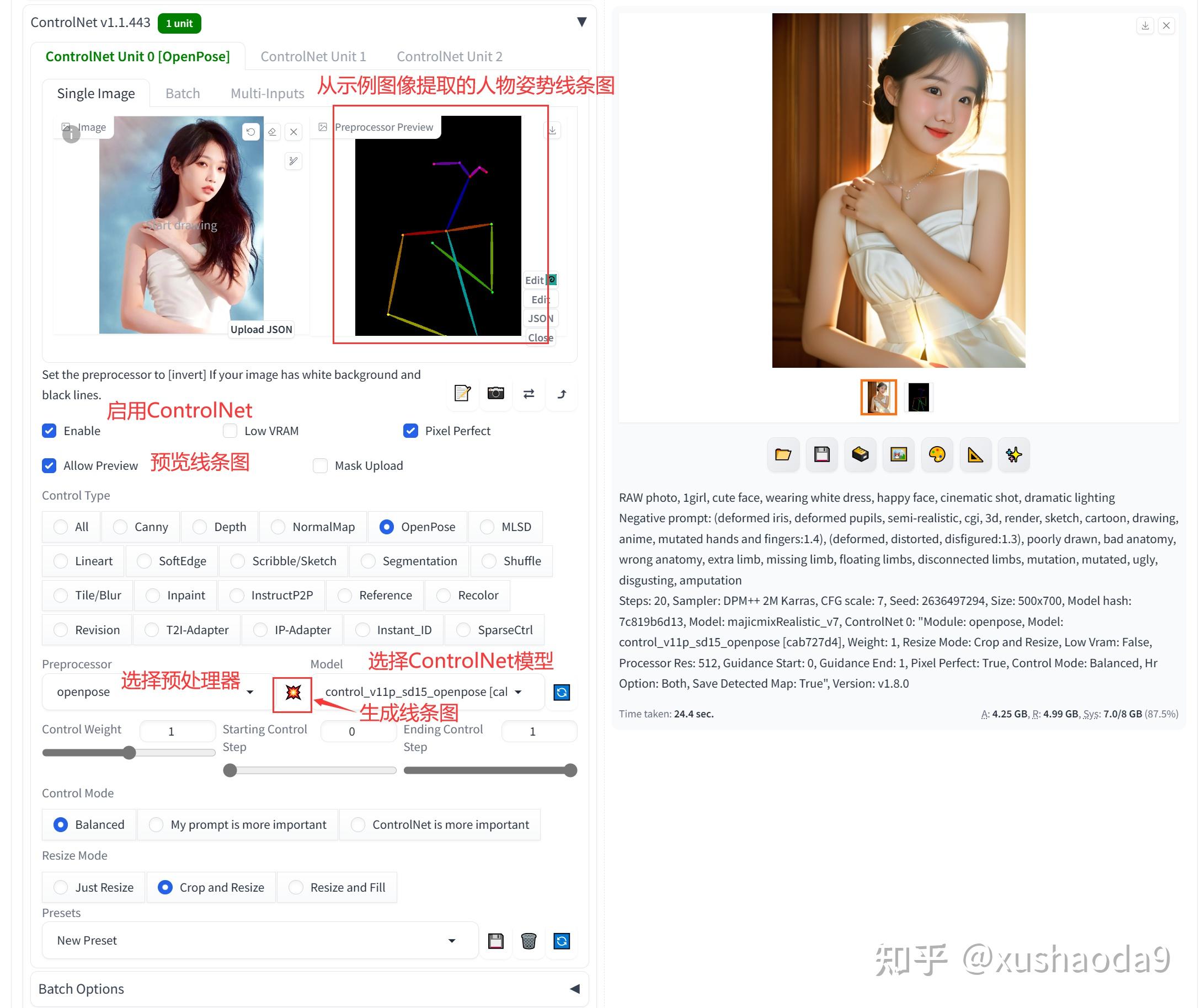
3、使用 Openpose 辅助绘图
- 点击上传示例图片
- 勾选Enable启用ControlNet
- 勾选 Allow Preview,显示线条图
- 在 Preprocessor 中,选择 openpose 预处理器
- 在 Model 中,选择 openpose 模型
- 点击右上角生成图片
即可看到 ControlNet 提取了人物姿势信息并生成线条图,生成的图像姿势跟给出的示例图片几乎相同
三、主要 ControlNet 控制模型(待更新)
1、Canny / Canny Edge(control_v11p_sd15_canny)
Canny Edge是一种多阶段的边缘检测算法,该算法可以从不同的视觉对象中提取有用的结构信息。Canny模型可以非常精准和细致的获取到原图的更多细节内容,包括毛发(头发)、衣服上的花纹等。使用canny模型可以对原图细节进行检测,让生成的图片可以获得更多细节还原,若想要更多的复刻图片,可以使用canny模型。
需要下载安装预处理器:dpt_hybrid-midas-501f0c75.pt
下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsmidasdpt_hybrid-midas-501f0c75.pt
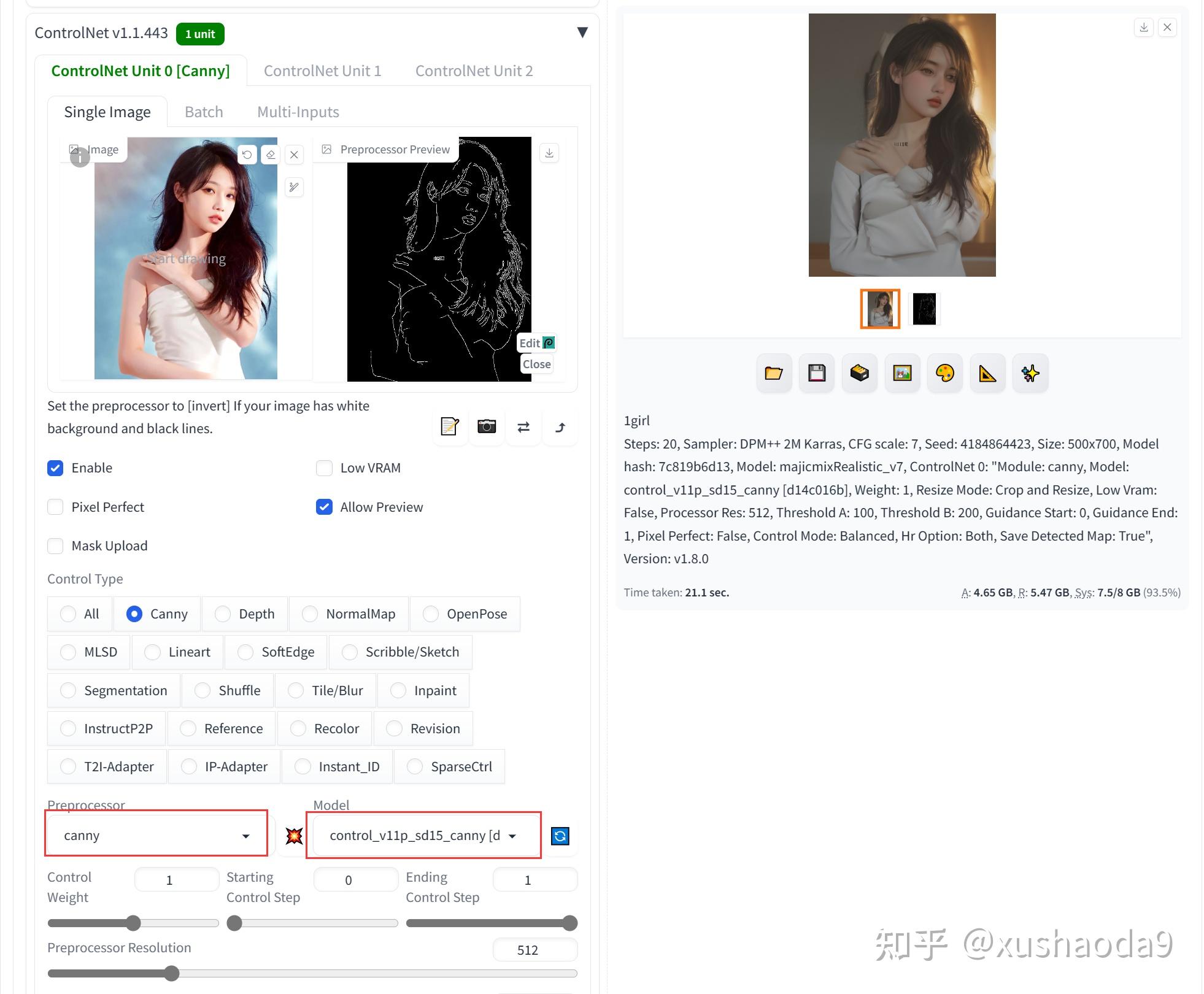
可以通过调整Canny low Threshold和Canny High Threshold的数值,让最终处理的结果精细度发生变化。
使用效果:
给出人物图像,提取线稿。AI基于线稿生成相应的图片。
2、Depth(control_v11f1p_sd15_depth):深度图
深度图也被称为距离影像,指的是图像采集器采集到图像中各个场景区域的距离,深度图会使用灰阶数值0~255组成图像,灰阶数值为0的区域表示图像中最远的区域,灰阶数值255表示图像中最近的区域,所以我们在深度图中可以看到不同灰度的区域组成的图像。
使用该模型需要下载预处理器:
- depth_midas:对应预处理器 dpt_hybrid-midas-501f0c75.pt,下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsmidasdpt_hybrid-midas-501f0c75.pt
- depth_anything:对应预处理器 dpt_hybrid-midas-501f0c75.pth(https://huggingface.co/spaces/LiheYoung/Depth-Anything/blob/main/checkpoints/depth_anything_vitl14.pth),下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsdepth_anythingdepth_anything_vitl14.pth
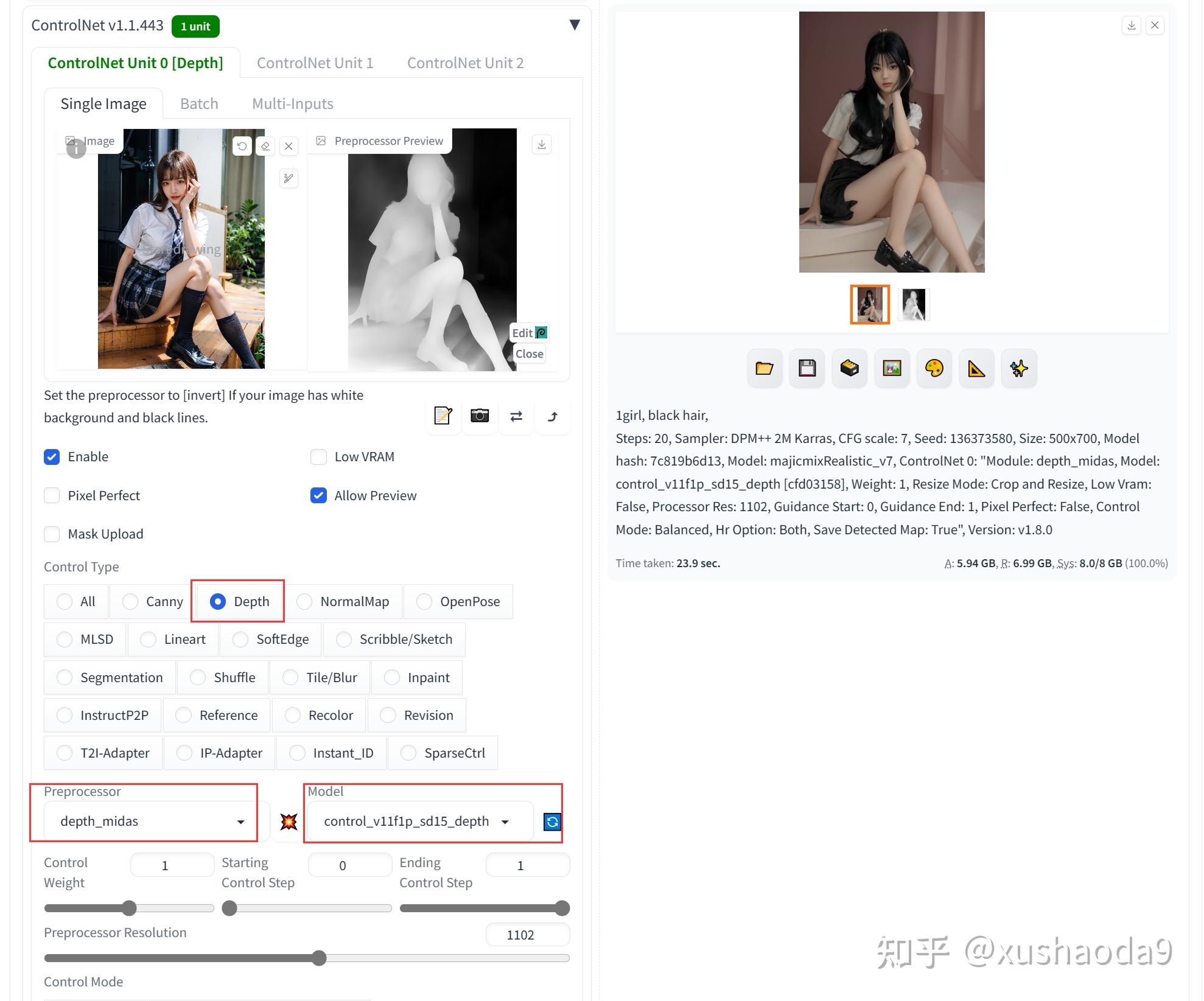
使用效果:
通过给出的人物样例图像,生成对应的深度图效果,基于深度图绘制的图片基本具有类似的姿势和背景。
3、NormalMap / Normal Bae(control_v11p_sd15_normalbae):法线贴图
NormalMap(法线贴图)需要搭配模型control_v11p_sd15_normalbae一起使用),法线贴图是一种凹凸贴图,会生成特殊的纹理,把表面细节通过光线表现出来,所以使用Normal_bae预处理器也有3个好处:1、Normal_bae可以更好的还原原图的光影;2、Normal_bae可以不保留太多原图细节,让新生成的图不至于和原图一模一样;3、Normal_bae可以保留更多光影信息,让图片看着更有细节。
使用该模型需要下载预处理器
- scannet.pt(https://huggingface.co/lllyasviel/Annotators/resolve/main/scannet.pt),下载好的文件放入指定文件夹:table-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsnormal_baescannet.pt
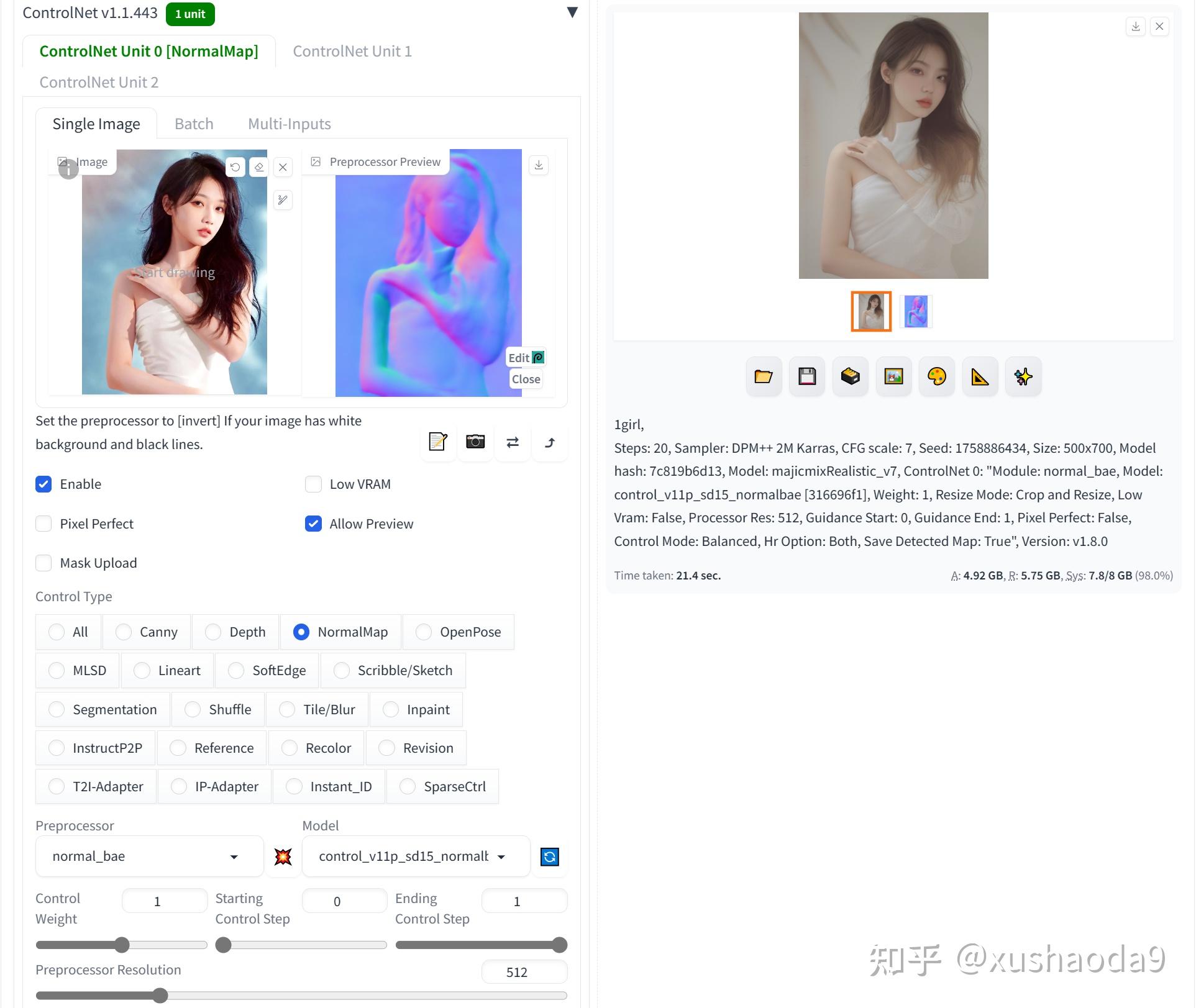
使用效果:
通过给出的人物样例图像,生成对应的法线贴图效果。
4、OpenPose / Human Pose(control_v11p_sd15_openpose):动作姿势
OpenPose人体姿态识别项目是美国卡耐基梅隆大学(CMU)基于卷积神经网络和监督学习并以caffe为框架开发的开源库。可以实现人体动作、面部表情、手指运动等姿态估计。
人体姿态估计,pose estimation,就是通过将图片中已检测到的人体关键点正确的联系起来,从而估计人体姿态。
使用该模型需要下载预处理器
- body_pose_model.pth
- facenet.pth
- hand_pose_model.pth
下载好的文件放入指定文件夹:**stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsopenpose***
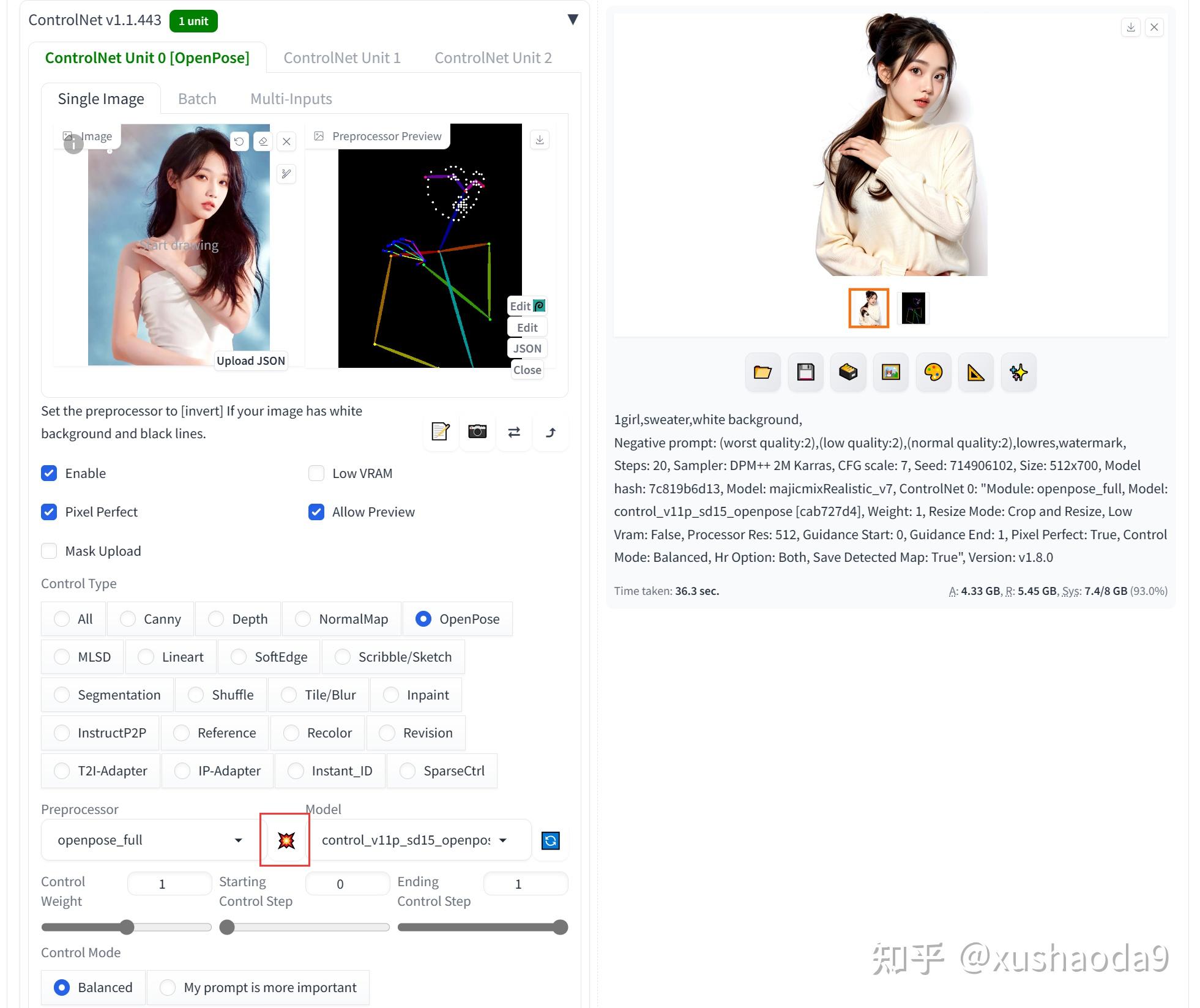
使用效果:
通过给出的人物样例图像,生成对应的人体姿态图,基于姿态图绘制的图像,具有和样例图片相同的姿势。
5、MLSD / M-LSD Lines(control_v11p_sd15_mlsd):边缘检测
M-LSD Lines是另一种轻量化的边缘检测算法,擅长提取图像中的直线线条。MLSD模型在建筑、室内方向的处理上是比较好的选择。
使用该模型需要下载预处理器:mlsd_large_512_fp32.pth
下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsmlsdmlsd_large_512_fp32.pth
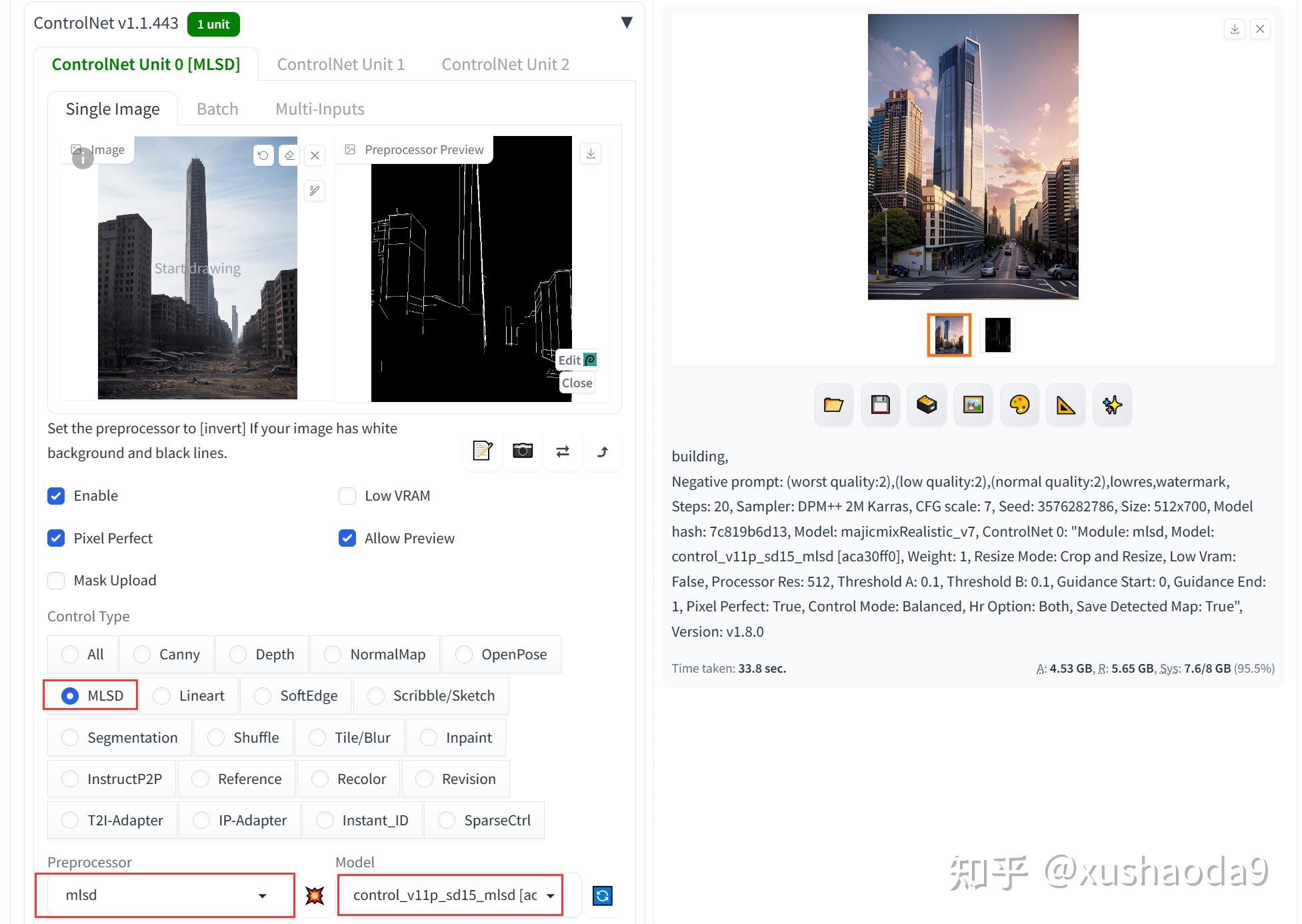
使用效果:
给出建筑图像,提取直线线条。AI基于线条图生成相应的建筑图片。
6、Lineart:真实线稿
Lineart模型与Canny模型大同小异,都可以检测出原图中的线稿。从最终出图效果来看,Lineart模型的表现效果不如Canny模型的效果好
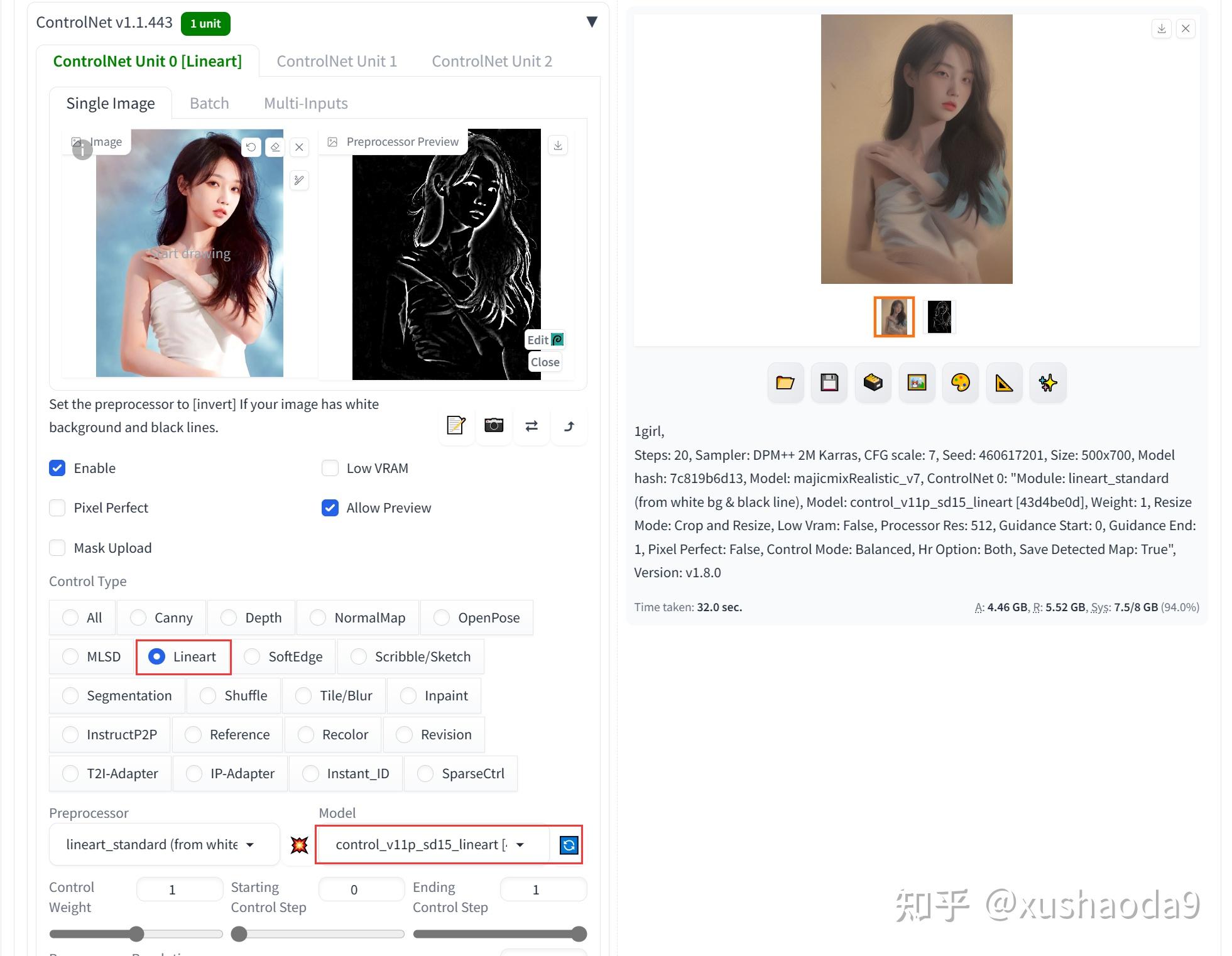
7、SoftEdge:柔和边缘
SoftEdge即软边缘检测,SoftEdge可以检测到原图边缘轮廓信息,原图主要的轮廓框架都会检测到,但不会像Canny 那样检测的特别细节,这也便于在生成新图片时,相比原图产生更多的变化。
使用该模型需要下载预处理器
- table5_pidinet.pth(https://huggingface.co/lllyasviel/Annotators/tree/main),下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadshedControlNetHED.pth
- ControlNetHED.pth(https://huggingface.co/lllyasviel/Annotators/blob/main/ControlNetHED.pth),下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadspidinettable5_pidinet.pth
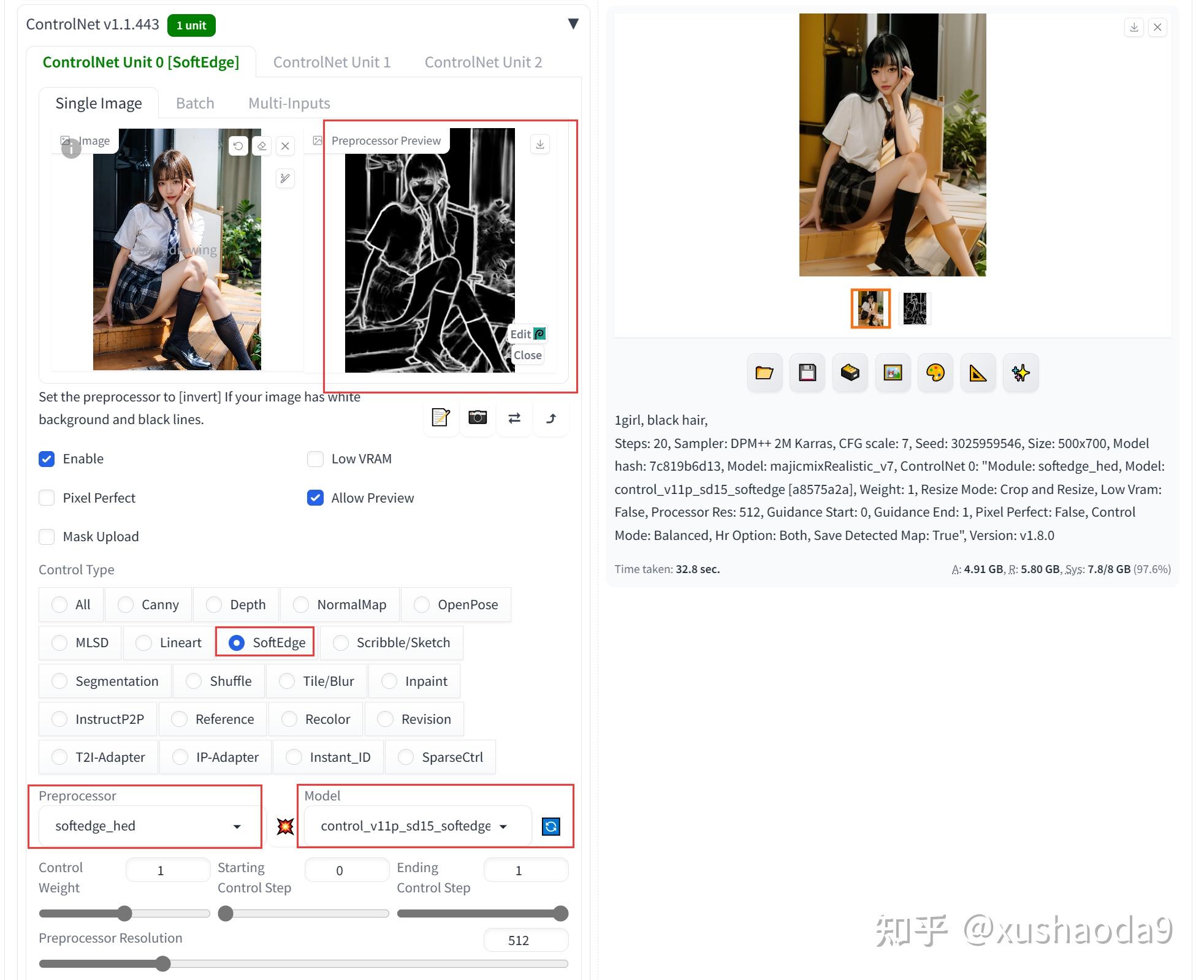
使用效果:
通过给出的人物样例图像,生成对应的粗线条稿。再生成类似的图像。
8、Scribble / Sketch / User Scribbles:涂鸦乱画
Scribble涂鸦模型也是一个检测图像边缘的模型,但是Scribble(涂鸦)的检测更为粗矿,只会检测原图大致的轮廓造型(目测感觉就20~30%的内容),但这也提供给了AI绘图极大的想象力发挥的空间。
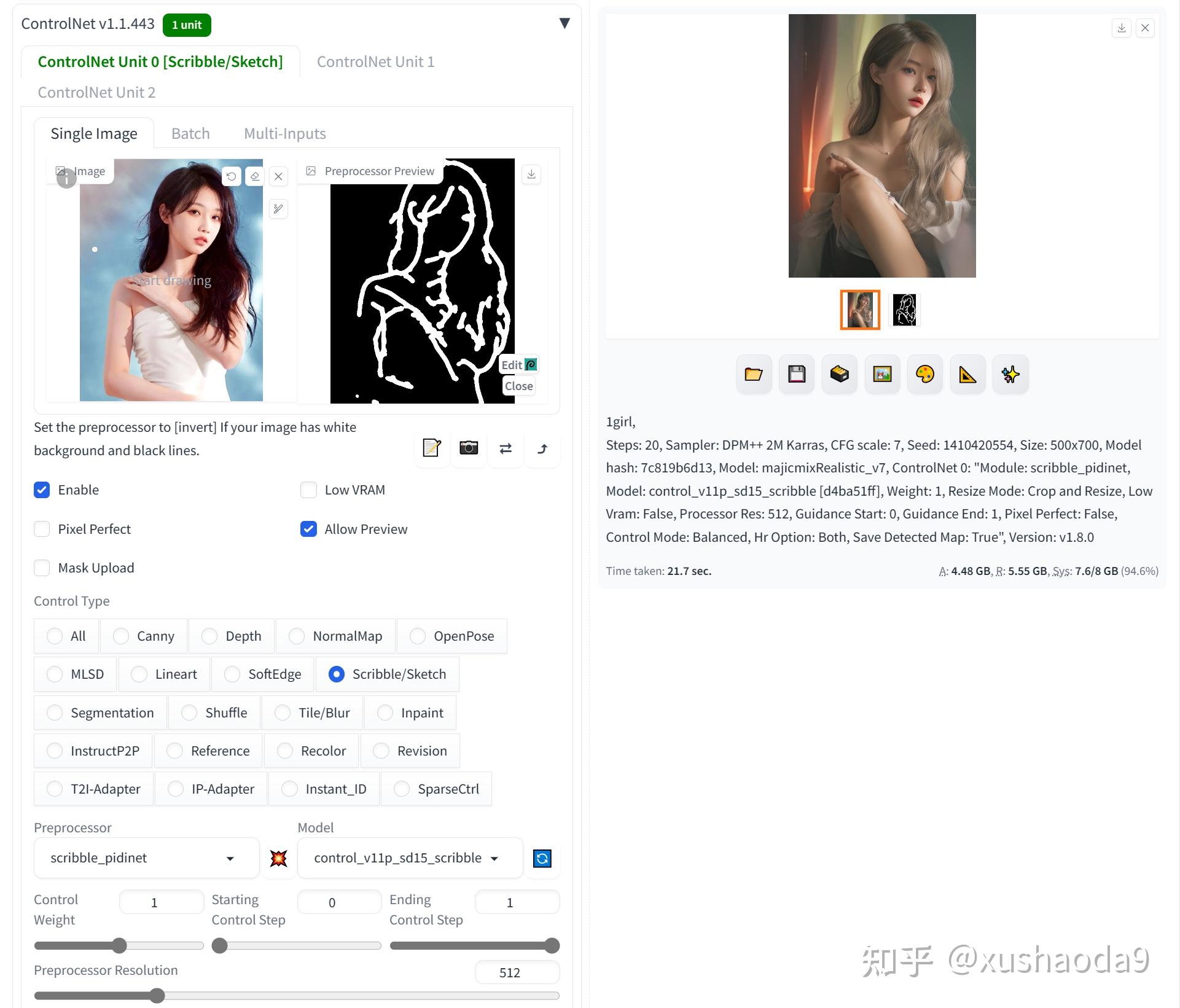
9、Semantic Segmentation(control_v11p_sd15_seg):语义分隔
Semantic Segmentation 模型可以把原图中的元素按类别进行分割处理,例如我们看到的天空、树木、河流、房屋等元素会被归纳为一类,不会展示元素的细节内容。
Semantic Segmentation 模型的优势在于可以获取到原图中元素信息以及位置且无过多细节,后续新生成图片时,可以很好的基于分割的模块进行图片生成,也不会有过多的原图元素干扰。
使用该模型需要下载预处理器:
- 250_16_swin_l_oneformer_ade20k_160k.pth
- 下载地址(https://huggingface.co/lllyasviel/Annotators/blob/main/250_16_swin_l_oneformer_ade20k_160k.pth)
- 下载好的文件放入指定文件夹:stable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsoneformer250_16_swin_l_oneformer_ade20k_160k.pth
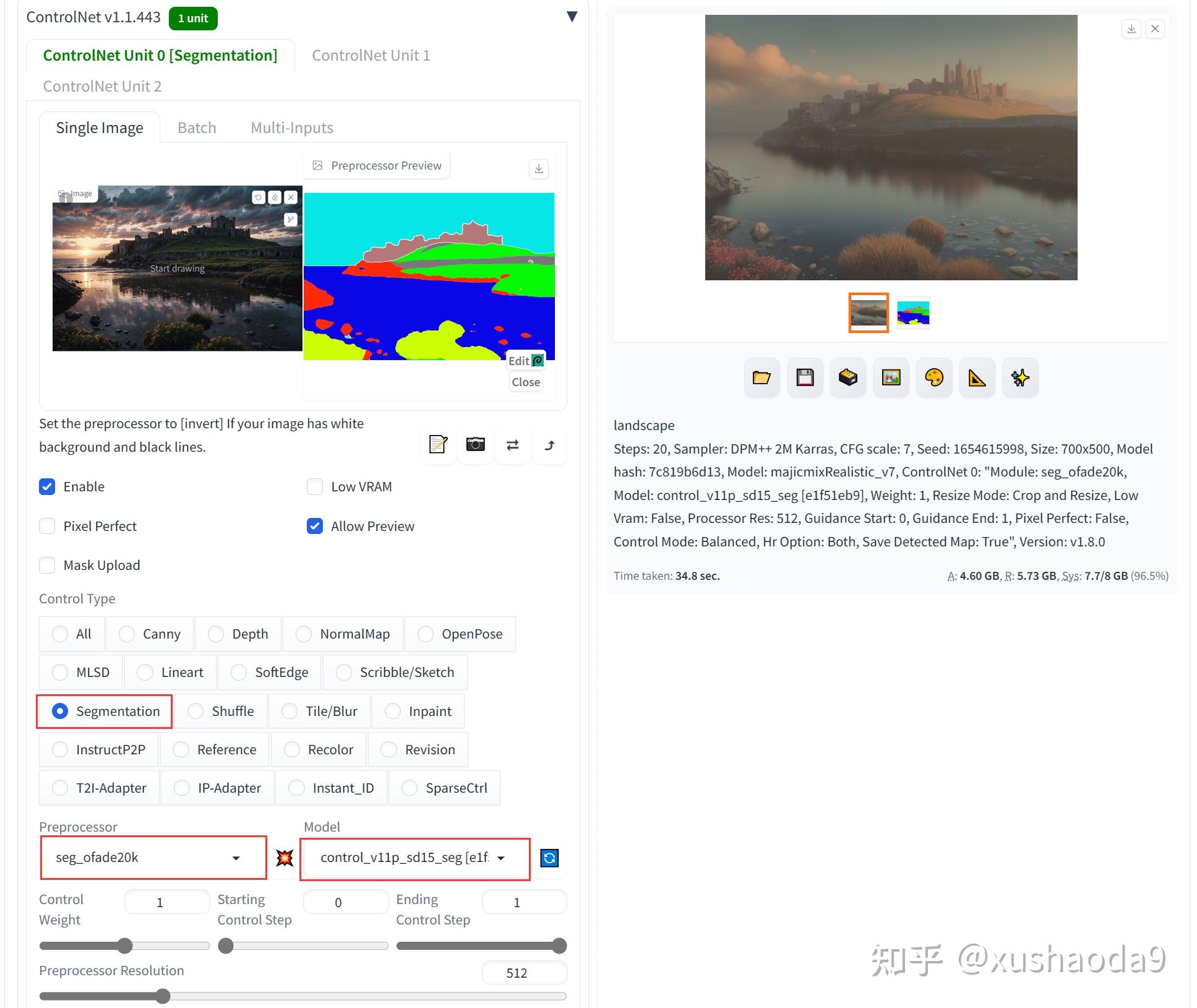
使用效果:
导入一张风景图片,使用预处理器“seg_ofade20k”,选择模型“control_v11p_sd15_seg”,勾选“启用”、“Pixel Perfect”、“Allow Preview”,再点击“爆炸”按钮进行分割后图片预览。
根据分隔的图形生成类似的图像。
HED Boundary
User Scribbles
Fake Scribbles
Anime Line Drawing
Revision
D:AiPaintingstable-diffusion-webuiextensionssd-webui-controlnetannotatordownloadsclip_visionclip_g.pth


